|
Project Database
Data from the Mara Hyena project are available for download on this site formatted as CSV files (see link below). See the README file for details. We continually incorporate diverse data collected in the field and the laboratory into a relational database. A half-time database manager currently oversees data entry personnel as they update the database with information from new and archived field notes. Most numerical data (from study areas in Amboseli & Masai Mara parks) covering the home ranges of five different clans are now available in our database. This permits integration of multiple types of data collected from the same individuals during the same or contrasting time periods, as well as comparisons between members of our different study populations. The database includes records from our first observations in 1988, and demographic records for each study clan, as well as less detailed information on hundreds of peripheral hyenas. Every observation is given a location in relationship to known landmarks as well as GPS coordinates. There are over 61,000 session records currently in the database representing many thousands of hours of hyena behavior observed during 15 years of study. Results from lab work such as genetic analysis or hormonal assays are also incorporated and linked to field data. Improved access to archived data has already vastly improved our productivity by enhancing our ability to query the database in testing specific hypotheses.
Our database is made of many core and auxiliary tables (see figure below). For example, one core table contains observation 'sessions': a start and stop time for the session, the hyenas present, other carnivores present, the geographic location, the context, and other data. From this hub we link to data about which individuals were present, geographic location, predators present, behavior taking place, etc. At any of these moments we can determine the age of any individual as well as which exact family members were present. 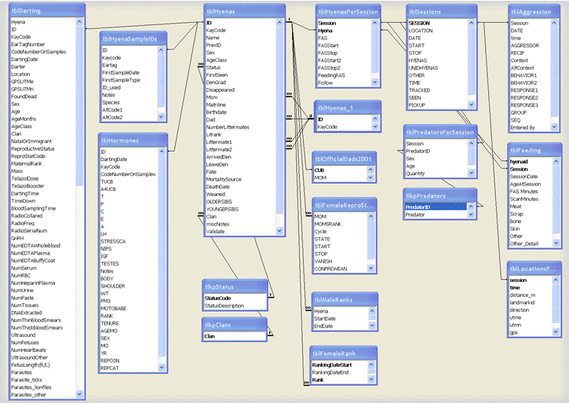
|